Essay · AI & Science
Look Up
Why AI Should Be Pointed at the Stars, Not at Itself
1. The Meta-Game
There is a peculiar circularity at the heart of most AI research today: we are using AI to make AI better at being AI. The largest labs in the world — staffed by brilliant people with access to extraordinary compute — are spending the overwhelming majority of their resources on a closed loop. Train a model. Evaluate it on benchmarks. Find where it falls short. Train a better model. Evaluate it again. Celebrate the delta.
I don't say this to diminish the work. Model improvement matters. The jump from GPT-3 to GPT-4 mattered. The jump from Claude 2 to Claude 3 mattered. These are genuine engineering achievements with real downstream consequences. But somewhere along the way, the benchmarks became the point. Every fraction of a point on MMLU is announced with fanfare. Every new coding eval is parsed like election returns. The AI community has developed an extraordinarily sophisticated infrastructure for measuring how well AI systems perform on tests — and a remarkably thin one for measuring whether those systems are helping us understand anything new about the world.
The ratio is wildly off. For every dollar spent asking "can this model solve competitive programming problems faster?" there is approximately zero dollars spent asking "can this model help us figure out what dark energy is?" For every researcher fine-tuning a model to improve its score on a math benchmark, there is almost no one pointing that same model at an unsolved problem in physics and saying: help me think about this.
The benchmark treadmill is real, and it is expensive. Not because it doesn't produce value — it does — but because of the opportunity cost. Every GPU-hour spent on the meta-game is a GPU-hour not spent on the actual game: understanding the universe we live in.
2. What Happens When You Look Up
I want to tell you what happens when you stop optimizing benchmarks and start using AI for real scientific work. Not hypothetically. Not as a thought experiment. I want to tell you what actually happened, in this project, over the past year.
The BigBounce research program is a one-person cosmology operation. One independent researcher — me — working with current-generation AI systems to investigate whether the universe began with a bounce rather than a singularity. Not a toy problem. Not a demonstration. A genuine research program investigating alternatives to the standard inflationary paradigm, using the same mathematical frameworks and observational datasets that institutional cosmology groups use.
Here is what one person with AI tools has accomplished:
This is not hypothetical. This is not a demo. This is a functioning research program that has produced falsifiable predictions, run serious statistical analyses, and built a complete infrastructure for cosmological investigation — all powered by one researcher working with the AI systems that already exist today.
The tools didn't need to get better. They needed someone to point them at something that mattered.
3. The Research Amplifier
Let me be clear about something: AI is not replacing scientists. That framing is wrong, and it misses the point entirely. What AI does — what it actually does when you use it seriously — is multiply what one person can accomplish. It is a research amplifier.
What used to require a lab of twenty people can now be done by one researcher with the right tools and the right questions. Not because the AI is smarter than twenty scientists. It isn't. But because it can handle the volume. It can run the literature review at scale. It can check dimensional consistency across a hundred equations in seconds. It can explore parameter spaces that would take a graduate student months. It can classify 195,000 spectral anomalies while you sleep.
The key insight — the one that I think the AI industry has largely missed — is this:
The Sweet Spot
AI is at its most powerful when pointed at domains where the questions are hard but the verification is clear. Science is exactly that domain. The math is precise. The predictions are falsifiable. The data is public. And the stakes — understanding the actual universe — could not be higher.
Cosmology, in particular, is almost perfectly suited to AI-assisted research. The theoretical frameworks are well-defined (general relativity, quantum field theory, statistical mechanics). The observational data is abundant and public (Planck, DESI, NANOGrav). The predictions are quantitative and testable (SPHEREx will measure \(f_{NL}\) to sub-unity precision). And the unsolved problems are genuine — not artificial benchmarks designed to test AI, but real questions about the structure and origin of the cosmos.
When you combine a human who knows which questions to ask with an AI that can process, derive, compute, and classify at scale, you get something that didn't exist before: an independent research program that operates at institutional scale with individual overhead.
4. What the Labs Are Missing
Imagine if one percent of the compute currently spent on benchmark optimization were redirected to actual scientific questions. Not one percent of revenue. One percent of compute. A rounding error in the training budget of a frontier lab.
The infrastructure already exists. Every major AI lab has access to:
Computational Tools
- MCMC samplers and Bayesian inference engines
- Spectral analysis and signal processing pipelines
- Anomaly detection and classification systems
- Symbolic mathematics and equation derivation
- Parameter sweep and optimization frameworks
AI Capabilities
- Literature review across thousands of papers
- Equation derivation and dimensional consistency checks
- Data classification at astronomical scale
- Cross-referencing observational datasets
- Writing, structuring, and reviewing manuscripts
AI can do literature review. It can derive equations. It can check dimensional consistency. It can run parameter sweeps. It can classify astronomical objects. It can draft papers, identify gaps in arguments, and suggest next steps. All of this works right now, with current models, without any special fine-tuning.
But it needs a human asking the right questions and verifying the answers. That is the irreplaceable part. The AI doesn't know what's interesting. It doesn't have taste, or intuition about which directions are promising, or the judgment to know when a result is genuinely surprising versus a numerical artifact. The human provides the direction. The AI provides the throughput. Together, they do science.
What the labs are missing is not capability. It is ambition. They have built the most powerful cognitive tools in human history, and they are using them to grade homework.
5. The Real Benchmark
Here is the benchmark that actually matters: does AI help us understand reality?
Not "can it pass the bar exam." Not "can it write code that compiles." Not "did its MMLU score go up by two points." Those are fine as intermediate metrics, useful for engineering purposes. But they are not the point. They were never supposed to be the point.
The real eval is out there, waiting:
~2028
SPHEREx
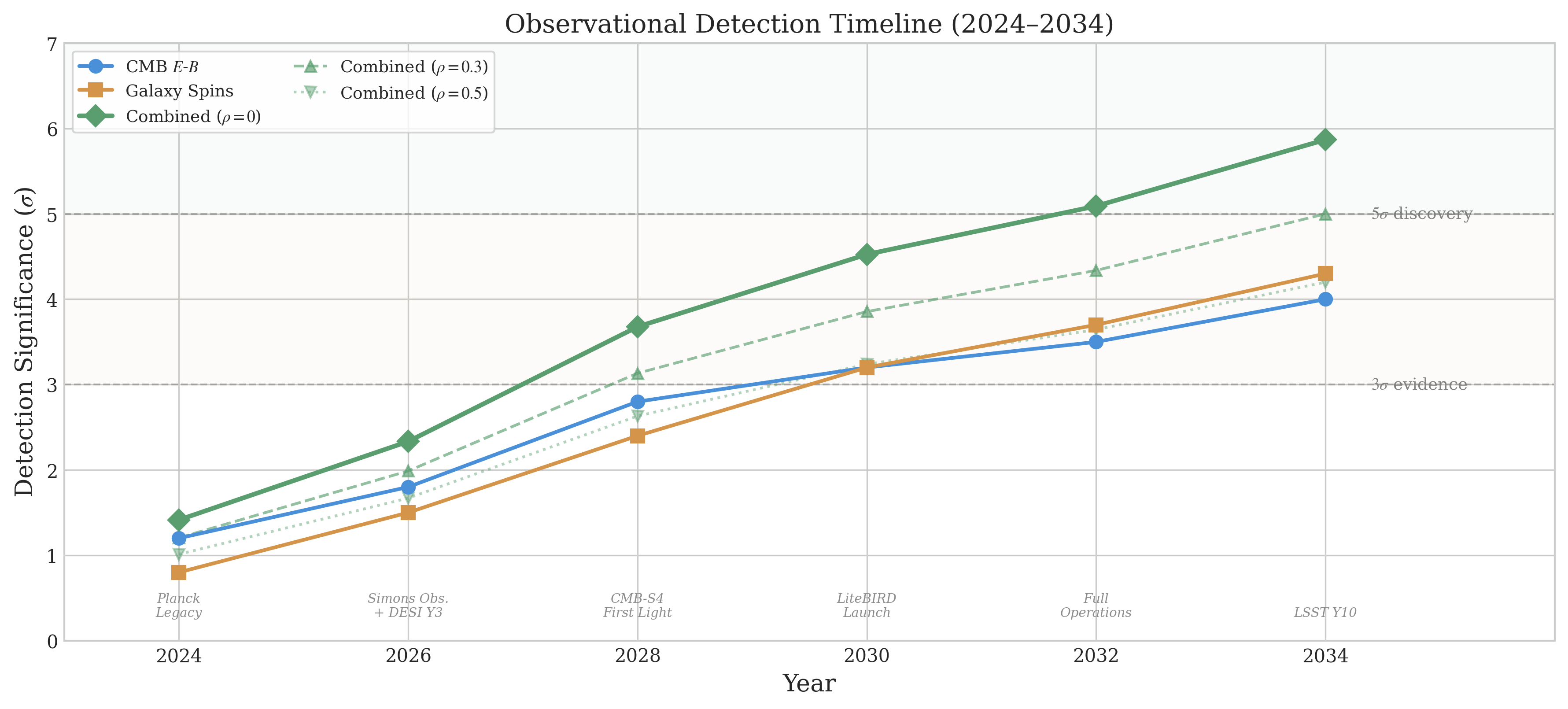
NASA's all-sky spectral survey will measure \(f_{NL}^{\rm local}\) to sub-unity precision. If the matter-bounce prediction of \(f_{NL} = -35/8\) is confirmed at \(\geq 5\sigma\), that is new physics — discovered in part through AI-assisted research.
~2030
LiteBIRD
JAXA's CMB polarization satellite will probe primordial gravitational waves and B-mode signals, directly testing inflationary predictions and constraining bounce alternatives.
These are real experiments. Real satellites. Real data. They will test real predictions made by real theoretical frameworks — including predictions that emerged from this AI-assisted research program.
If the matter-bounce prediction \(f_{NL} = -35/8\) is confirmed at \(5\sigma\), that is not a benchmark score. That is not a leaderboard position. That is new physics. A fundamental insight into the origin of the universe, derived through a collaboration between human intuition and machine computation.
That is the scoreboard that matters.
6. A Call to Curiosity
This essay is not about one research project. The BigBounce program is a proof of concept, not a destination. It demonstrates something that should be obvious but apparently is not: the AI systems we have right now are capable of contributing to serious scientific research. They are ready. The question is whether we are ready to use them for that purpose.
Every researcher with an AI subscription has a superpower they are not using. Every physicist, biologist, chemist, and astronomer who has access to a frontier language model has a research amplifier sitting on their desk, waiting to be aimed at something real. The tool is there. The questions are there. The gap is in between.
The questions are enormous and open:
- What is dark energy, and why is the universe accelerating?
- What happens to physics at the Planck scale? Is there a quantum theory of gravity?
- How did cosmic structure emerge? Was inflation the mechanism, or something else?
- Why is there more matter than antimatter?
- What is the topology of the universe? Is it finite or infinite?
These are not rhetorical questions. They are research programs waiting to happen. And for the first time in history, the barrier to entry is not institutional affiliation or access to a particle accelerator. It is curiosity and rigor.
Stop optimizing. Start wondering. Look up.
"The universe is under no obligation to make sense to you — but you are under every obligation to try. And now, for the first time, you have tools that can help you try at a scale that was previously impossible. Use them. Not to climb leaderboards. To climb toward understanding."